데이터 사이언스
[Kafka] 간단하게 보는 Kafka 등장 배경, 특징, 활용 사례
메가구글
2023. 6. 1. 19:25
1. Kafka 등장배경
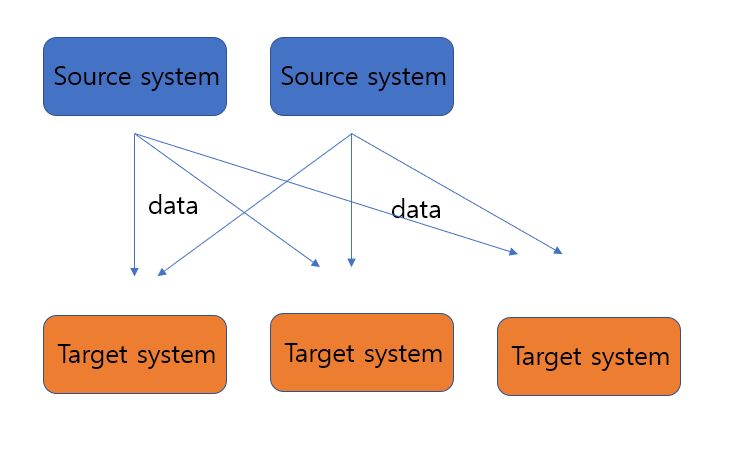
처음에는 그림 첫 번째와 같이 간단한 통신 시스템을 만들었다고 생각하자.
Source system과 Target system을 1:1로 연결하면 되기 때문에 문제가 없어 보인다.
하지만 두 번째 사진처럼 Source sytem이 2개로 늘어나고, Target system을 3개로 늘리게 된다.
처음에는 연결이 한 개였지만 갑자기 연결이 6개로 늘어났다.
갑자기 시스템이 복잡하게 되기 시작한다.
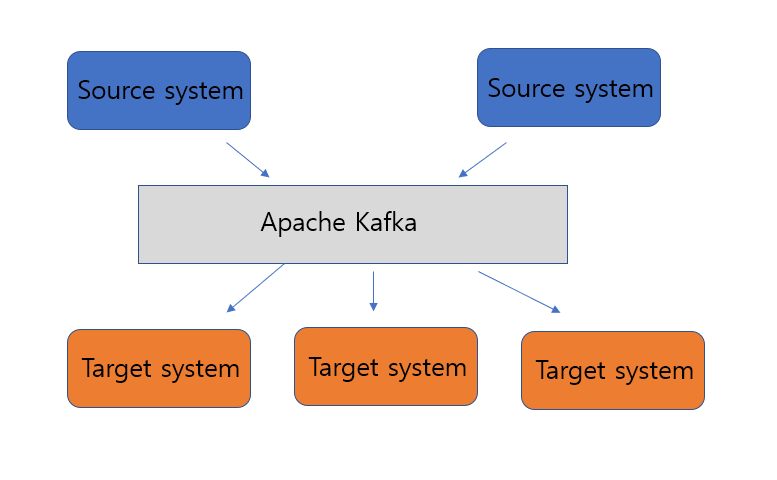
그래서 Source는 보내기만 하고, Target 쪽에서는 알아서 읽게만 만들고 중간에 중재해 주는 것을 만들면 어떨까?
라는 생각에 등장하게 된 개념이 Apache Kafka이다.
중간에 시스템이 한 개가 생김으로써 Source와 Target은 일명 decoupling이 된다.

2. Kafa 특징
- 분산되어 있고(Distributed), 탄력적 아키텍처 (Resilent architecture), 결함 허용(fault tolerance)
- 수평 스케일링(Horizontal scalability) 혹은 Scale out으로 불린다.
- Scale out : 장비를 추가해서 확장하는 방식
- horizontal scaling : 서버를 추가해 확장
- 최대 100 broker(서버) 추가 가능
- 초당 수백만 개의 메시지 허용 가능하다.
- 높은 성능 (지연시간 10ms 보다 작음) - 실시간
- 여러 회사에서 Kafka를 사용중 (AirBnB , Netflix, LinkedIn, Uber, WalMart)
3. Kafka 사용 사례
- 메세지 시스템
- 활동 기록 (activity tracking)
- 다양한 다른 지역에서 메트릭 수집
- 애플리케이션 로그 모음
- 스트림 프로세싱 (Kafka Stream Api or Spark 사용)
- 시스템 의존도 낮추기 디커플링
- Spark, Flink, Storm, Hadoop, 등과 통합
Reference
LinkedIn / Stephane Maarek / Learn Apache Kafka for Beginners (2019)